The optimal knowledge creation strategy of organizations in groupthink situations
Namjun Cha, 황준석, Eungdo Kim (2020) · Computational and Mathematical Organization Theory · DOI ↗
조직의 합의 추구가 집단사고 으로 귀결되느냐 집단 지성 로 귀결되느냐를 결정하는 세 “switching factor” — 지식 갈등 (knowledge conflict), 재고 (reconsideration), 조직 기억 (organizational memory) — 을 정의하고, 50 agents · 100 cycles · 100 iterations 의 에이전트 기반 모형 시뮬레이션 + SFA (확률적 프론티어 분석) + 메타프론티어 분석 로 8 가지 전략 조합의 효율성 (TGR) 을 비교한다. 결과: 지식 갈등 + 재고 조합 (Group 2) 이 TGR 0.801 로 최고, 조직 기억 단독 (Group 4) 0.291, 지식 갈등 + 기억 (Group 7) 0.254 로 최저 군.
- RQ: 조직의 합의 추구를 groupthink 가 아닌 collective intelligence 로 전환하는 메커니즘 (switching factor) 은 무엇이며, 어느 조합이 가장 효율적인가?
- 방법론: 에이전트 기반 모형 (Langevin 확률 미분방정식 기반 지식 분포 진화), SFA (확률적 프론티어 분석), 메타프론티어 분석
- 데이터: ABM 시뮬레이션 (50 agents, 100 cycles, 100 iterations, network density 0.3); 8 sub-models × 시뮬레이션 결과 → SFA · MFA 입력
- 주요 발견: TGR 순위 — Group 2 (지식 갈등 + 재고): 0.801, Group 3 (재고 + 기억): 0.666, Group 5 (3 factor): 0.680, Group 6 (지식 갈등): 0.617, Group 8 (기억): 0.553, Group 4 (재고): 0.291, Group 7 (지식 갈등 + 기억): 0.254, Group 1 (reference / groupthink): 0.122.
- 시사점: 조직은 단순 합의 추구가 아닌 지식 갈등 + 재고의 조합으로 다양성을 유지해야 한다. 조직 기억은 단독 사용엔 효과 있으나 지식 갈등과 결합 시 evaluation 부재로 inefficiency 발생.
요약
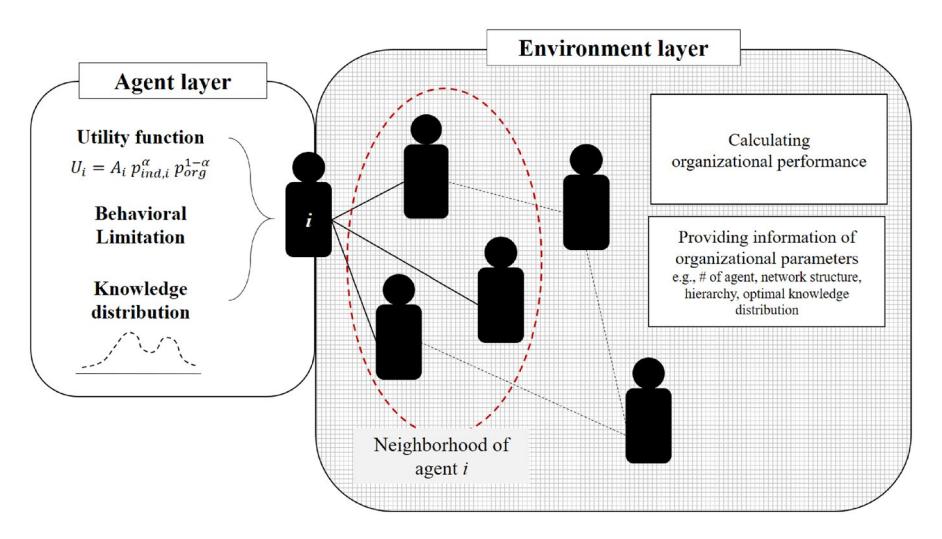
집단사고 의 Janis (1972) 모형은 응집성·구조적 결함·도발적 맥락 같은 antecedents 가 linear 하게 의사결정 실패로 이어진다고 보지만, Turner et al. (1992) 등의 비판처럼 이 linear 구조는 실증적으로 일관되게 지지받지 못했다. 한편 집단 지성 는 Lévy (1994) 이후 같은 “합의 추구” 를 emergence·complex adaptive system 프레임에서 다루며, 둘은 종착점만 다른 동일 출발의 두 결과로 볼 여지가 있다. 본 논문은 이 둘을 가르는 “switching factor” 세 가지를 정의한다. (i) 지식 갈등 (knowledge conflict): 이질성 점수 가 높은 두 agent 가 상호작용해 지식을 결합. (ii) 재고 (reconsideration): 기존 지식을 유지하고 더 많은 agent 와 상호작용해 학습을 지연. (iii) 조직 기억 (organizational memory): 모든 생성 지식이 시간 거리 에 따라 무작위 변형되어 누적.
방법론은 2 단계다. (1) ABM 시뮬레이션: 50 agents, 100 cycles, 100 iterations, network density 0.3, 효용 함수 (self-centeredness ~ U(0.5, 1.0), sensitivity K ~ U(0.1, 1.0)). 개별 agent 의 지식은 분포 로 표현되고 Langevin 식 의 drift + stochastic turbulence 로 시간에 따라 진화. 조직 지식은 , 품질 (). (2) MFA: 8 sub-models (3 factor 의 조합) 에 대해 각각 input (다양성, 학습 능력) 과 output (조직 지식 품질) 의 polynomial frontier 를 SFA 로 추정 후 MFA 로 group frontier 와 meta-frontier 간 TGR 계산.
핵심 결과 세 가지. (i) 단일 효과: 지식 갈등은 단기 성과를 크게 개선하지만 개인 지식의 다양성을 감소; 재고는 통계적 유의 효과 없으나 다양성 보존; 조직 기억은 초기에 성과·효용 향상 후 장기엔 감소 (낡은 지식 의존 → 변화 방해). (ii) TGR 순위: Group 2 (지식 갈등 + 재고) 0.801 로 최고, Group 5 (3 factor 결합) 0.680, Group 3 (재고 + 기억) 0.666 이 양호. Group 7 (지식 갈등 + 기억) 0.254, Group 4 (재고 단독) 0.291 이 최저. Group 1 (reference / 무 switching) 0.122 가 최저. (iii) Optimal strategy: 지식 갈등 + 재고가 우월하며 이는 이질적 지식과 만났을 때 (지식 갈등) 어느 정도 학습할지를 (재고) 결정하는 메커니즘이 보완적이기 때문. 반대로 지식 갈등 + 기억은 evaluation 부재로 누적 지식의 단순 모방을 증폭시켜 비효율. 결론은 조직의 collective intelligence 가 복잡·위험한 행위가 아닌 simple routine 의 조합 (지식 갈등 + 재고) 으로 형성된다는 것이다.
핵심 결과
| Group | Knowledge conflict | Reconsideration | Organizational memory | TE | TGR | TE* = TE × TGR |
|---|---|---|---|---|---|---|
| 1 | X | X | X | 0.991 | 0.122 | 0.121 |
| 2 | ○ | ○ | X | 0.988 | 0.801 | 0.792 |
| 3 | X | ○ | ○ | 0.998 | 0.666 | 0.662 |
| 4 | X | ○ | X | 0.997 | 0.291 | 0.291 |
| 5 | ○ | ○ | ○ | 0.995 | 0.680 | 0.677 |
| 6 | ○ | X | X | 0.997 | 0.617 | 0.616 |
| 7 | ○ | X | ○ | 0.998 | 0.254 | 0.253 |
| 8 | X | X | ○ | 0.994 | 0.553 | 0.550 |
- 최고 전략: Group 2 (지식 갈등 + 재고).
- 최악 전략: Group 7 (지식 갈등 + 기억), Group 4 (재고 단독).
- 단순 합의 (Group 1): TGR 0.122 로 명확한 baseline.
방법론 노트
개별 agent 의 지식 분포 는 Langevin 형 확률 미분방정식으로 진화한다.
drift term 는 utility 가 높은 다른 agent 의 지식 위치 기댓값 (학습), 는 시간에 따라 증가하는 stochastic turbulence (지식 불확실성) 다. 조직 지식 품질 (). 8 sub-models 의 효율성 추정은 polynomial SFA frontier
(, ) 로 그룹별 추정. Meta-frontier 는 8 그룹 frontier 를 envelope 한 후 계산, 전체 효율성 . FRONTIER 4.1 + MATLAB R2017a 사용. Saltelli et al. (2008) 의 sensitivity 분석으로 robustness 확인.
연구 계보
황준석 그룹의 에이전트 기반 모형 · 시뮬레이션 방법론 라인의 조직 이론 응용이다. 동일 1 저자의 전작 How to Improve Performance and Diversity of Government-Funded Research Institute Ecosystem? Focus on Result Sharing and Feedback Policy (GI 평가 시스템 ABM) 의 방법론적 확장으로, GA 기반 단순 모방 학습에서 Langevin 확률 미분방정식 + ABM 으로 진화했다. Janis (1972, 1982) 의 groupthink 모형 비판, Solomon (2006), Surowiecki (2004) 의 collective intelligence 와 다양성·분권화 강조, March (1991) 의 exploration-exploitation, Kluger and DeNisi (1996) 의 feedback meta-analysis 를 조직 학습 시뮬레이션으로 종합한다. TEMEP 내에서는 ABM + 효율성 분석 (SFA·MFA) 의 결합이라는 패턴을 후속 작업 (Sustainability of ride-hailing services in China's mobility market: A simulation model of socio-technical system transition 등) 에 제공한다.
See also
- 황준석
- Namjun Cha
- 에이전트 기반 모형
- 지식 경영
- 지식 창출
- 집단사고
- 집단 지성
- SFA (확률적 프론티어 분석)
- 메타프론티어 분석
- Computational and Mathematical Organization Theory
- How to Improve Performance and Diversity of Government-Funded Research Institute Ecosystem? Focus on Result Sharing and Feedback Policy
인접 그래프
- 인물 3
- 방법론 3
- 개념 4
- 수록처 1
- 분류 1
- 논문 2