Exploring knowledge management technologies to enhance sustainability and mitigate technostress from a collaborative perspective
Jihye Lim, 황준석 (2024) · Journal of Knowledge Management 30:448-467 · DOI ↗
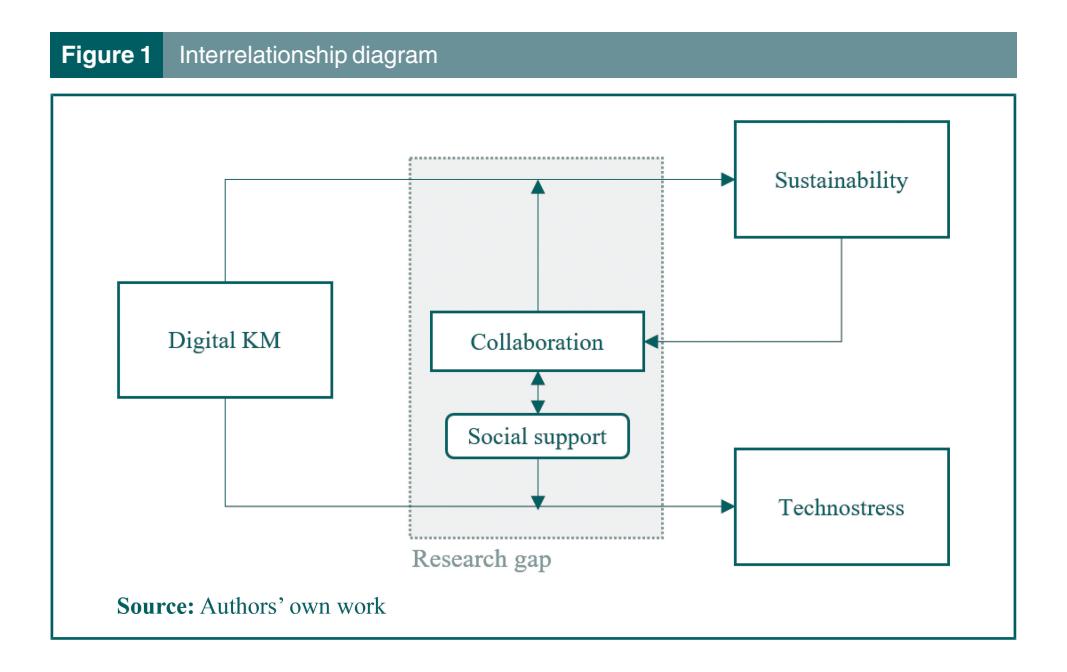
본 연구는 지식 경영 (KM) → Sustainability → 테크노스트레스 → collaboration 네 변수의 상호관계를 학술 논문 (Scopus 838 papers) 과 특허 (Google Patents 2,839 KM 특허 + 14,973 candidate 특허) 텍스트로 분석한다. BERTopic (SBERT + UMAP + HDBSCAN + cTF-IDF) 로 paper 10 topic, patent 47 topic 추출, patentsberta-similarity 로 KM-collaboration patent 와 candidate patent 간 cosine similarity 계산해 5 개 유망 기술 후보 (Ca1-Ca5: expertise collaboration, 공유 lab platform, virtual assistant knowledge search, user network recommendation, e-learning 개인화) 를 추천. 결과: AI·클라우드·빅데이터가 KM 협력 잠재력 확장, 사회적 지원 메커니즘으로 technostress 완화 가능.
- RQ: (1) KM 관련 특허의 topic 동향은? (2) collaboration 관점에서 KM 논문의 특성은? (3) collaborative + sustainable KM 을 위한 유망 기술은 무엇이며 어떤 분야에 적용 가능한가?
- 방법론: BERTopic (3 단계: sentence-bert-embedding → umap-dimension-reduction → hdbscan-clustering → ctf-idf topic representation), patentsberta-similarity (Bekamiri et al. 2024, 특허 augmented SBERT, cosine similarity for p2p), 토픽 모델링 (paper topic - patent topic 매핑)
- 데이터: Google Patents 198 KM 특허 + 그들이 인용한 2,879 까지 확장 → abstract 있는 2,839 KM patents; CPC G06F16/953 OR G06F9/486 기준 14,973 candidate patents (2020 이후 grant); Scopus KM × collaboration 키워드 조합으로 878 papers (English) → abstract 있는 838 papers; 8 KM journals + computer science journals
- 주요 발견: Paper 10 topics (university-industry collab 17.11%, organizational support 16.33%, supply chain 14.44%, online group study 13.50%, ontology/semantic web 13.19%, product design eng 8.16%, healthcare 6.28%, social media 5.34%, user recommendation 2.98%, big data/cloud 2.67%). Patent 47 topics → 7 clusters (data/semantic 32.47%, user/search 18.68%, account/transaction 15.42%, disease/biological 13.30%, risk/insurance 8.71%, problem/fault 7.56%, word/document 3.87%). Topic 36 (agent collaboration) 이 KM-collaboration target. 5 유망 candidate patents 추천 — Ca1 expertise collaboration (similarity 6.12), Ca2 shared lab platform (5.61), Ca3 virtual assistant search (5.37), Ca4 user network recommendation (4.34), Ca5 e-learning 개인화 (4.28).
- 시사점: AI·클라우드·빅데이터 채택 시 KM 의 협업·지속가능성 동시 강화 가능; 사회적 지원 (coworker support, sense of community) 이 technostress mitigation 의 핵심 매개; 조직은 기술 + 문화 + 인적 자원 의 통합 전략 필요.
요약
지속가능성 (sustainability) 의 추구는 monetary 이익을 넘어 social·environmental 가치를 포함하며, 지식 경영 (KM) 가 그 네 가지 핵심 enabler 중 첫 번째다 (Mohamed et al. 2009). 디지털 기술의 KM 도입은 process optimization·learning·knowledge sharing 을 통해 Sustainability 에 기여하지만, 동시에 직원의 테크노스트레스 — Tarafdar et al. (2020) 의 information overload·complexity 로부터 발생하는 stress — 를 유발한다 (Martínez-Navalon et al. 2023). Sustainability 의 세 기둥 (Purvis et al. 2019: 경제·사회·생태) 중 social 측면이 가장 덜 연구되었고, 본 연구는 collaboration 기반 social support 를 technostress 의 mitigation 메커니즘으로 가설화한다. Lanzl (2023) 의 사회적 지원 4 차원 (supervisor·coworker·community·family) 중 coworker support 와 sense of community at work 가 collaboration 과 직결되며, Hessari & Nategh (2022) 등이 technostress 완화 효과를 보였다. 연구 질문: 어떤 KM 기술이 collaboration 을 강화하면서 technostress 를 줄이고 sustainability 에 기여하는가?
방법은 4 단계: (1) 데이터 수집 — Google Patents 에서 ‘knowledge management’ 제목 검색으로 198 patents, 그들이 인용한 특허까지 확장해 2,879 → abstract 있는 2,839 KM patents; CPC G06F16/953 OR G06F9/486 기준 2020 이후 grant 14,973 candidate patents; Scopus KM × collaboration 키워드로 838 papers. (2) BERTopic 으로 paper 10 topics + patent 47 topics 추출. (3) Patent topic 36 (agent collaboration) 을 KM-collaboration target 으로 지정, patentsberta-similarity (Bekamiri et al. 2024) 로 cosine similarity 계산, 0.5 이상의 similarity 합을 score 로 사용해 candidate patent 랭킹. (4) 상위 5 candidate patent (Ca1-Ca5) 를 paper topic 과 매핑해 application area 제시. Bekamiri PatentSBERTa 는 SBERT 의 patent-augmented 버전으로, deep learning 기반 p2p 유사도 측정에 적합.
결과: Paper 의 top topic 은 university–industry collaboration (17.11%), organizational support (16.33%), supply chain (14.44%), online group study (13.50%) 순. Patent topic cluster 는 7 그룹 — data/semantic (32.47%), user/search (18.68% — target topic 36 포함), account/transaction (15.42%), disease/biological (13.30%), risk/insurance (8.71%), problem/fault (7.56%), word/document (3.87%). 추천된 5 candidate patents: Ca1 (expertise collaboration, sim 6.12) — university-industry / product design eng 적용; Ca2 (공유 lab platform, 5.61) — healthcare / social media; Ca3 (virtual assistant knowledge search, 5.37) — big data/cloud / organizational support; Ca4 (user network recommendation, 4.34) — supply chain / ontology semantic web; Ca5 (e-learning 개인화, 4.28) — user recommendation / online group study. 핵심 통찰: AI·cloud·big data 가 KM 의 collaboration 잠재력을 확장하며, 사회적 지원 메커니즘이 technostress 완화의 매개. Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT 자매 작업과 동일 BERTopic 파이프라인 공유. 황준석 의 5기 (2024-2026) topic modeling·기술 동향 분석 라인의 작업.
핵심 결과
| 유망 patent | 유사도 점수 | 기능 | Application area (paper topic) |
|---|---|---|---|
| Ca1 | 6.12 | Expertise collaboration system | University-industry collaboration, Product design engineering |
| Ca2 | 5.61 | 공유 lab platform 기반 data 관리 | Healthcare, Social media |
| Ca3 | 5.37 | Virtual assistant 기반 knowledge search | Big data/cloud, Organizational support |
| Ca4 | 4.34 | User network 기반 정보 recommendation | Supply chain innovation, Ontology/semantic web |
| Ca5 | 4.28 | E-learning 개인화 학습 자원 추천 | User recommendation, Online group study |
| Paper topic | Share | Patent cluster | 비중 |
|---|---|---|---|
| University-industry collab | 17.11% | Data/semantic | 32.47% |
| Organizational support | 16.33% | User/search (target 36) | 18.68% |
| Supply chain innovation | 14.44% | Account/transaction | 15.42% |
| Online group study | 13.50% | Disease/biological | 13.30% |
| Ontology/semantic web | 13.19% | Risk/insurance | 8.71% |
| Big data/cloud | 2.67% | Problem/fault | 7.56% |
- 데이터: 838 papers (Scopus), 2,839 KM patents + 14,973 candidate (Google Patents)
- 국가별 KM patent share: US ~48%, China·Japan·Korea 다음
- 정상 KM journal: Knowledge Management Research and Practice (12), Journal of Knowledge Management (11)
방법론 노트
BERTopic (Grootendorst 2022) 의 3 단계 파이프라인은 다음과 같다:
여기서 sentence-bert-embedding (SBERT, Reimers & Gurevych 2019) 는 BERT 의 Siamese/triplet network 변형으로 문장 의미 비교를 효율적으로 수행. umap-dimension-reduction (McInnes et al. 2018) 은 고차원 embedding 을 클러스터링에 적합한 저차원으로 축소. hdbscan-clustering (McInnes et al. 2017) 은 density-based 라 outlier 처리에 강건. ctf-idf (cTF-IDF) 는 일반 TF-IDF 의 cluster 단위 일반화 — 단일 문서가 아닌 cluster 의 word importance 를 측정.
patentsberta-similarity (Bekamiri et al. 2024) 는 SBERT 를 patent text 로 fine-tuning 한 모델로 p2p 유사도 계산에 사용:
각 candidate patent 의 score 는 0.5 이상 유사도의 합:
식별 strategy: (i) BERTopic 의 pretrained model 이 sparse data 에서도 LDA 보다 robust 한 topic 식별 가능, (ii) cosine similarity 0.5 threshold 로 noise 제거, (iii) patent–paper topic 매핑으로 기술의 application area 를 데이터 driven 으로 도출. 한계: (a) Scopus 기반이라 다른 DB (WoS, IEEE Xplore) 누락 가능, (b) title-only 검색이라 body 만 키워드 포함한 paper 제외, (c) KM 외 기술의 technostress 효과 일반화 불가, (d) sustainability 3 pillar 중 social 만 집중 분석.
연구 계보
이론 기반은 지식 경영 와 Sustainability 의 관계 (Mohamed et al. 2009; Lopez-Torres et al. 2019; Yan et al. 2023), Sustainability 의 3-pillar framework (Purvis et al. 2019; Gelashvili et al. 2024 의 social pillar 강조), 테크노스트레스 의 Tarafdar et al. (2020) 정의, Lanzl (2023) 의 사회적 지원 4 차원 분류, Hessari & Nategh (2022) 의 coworker support → technostress 감소 라인. BERTopic 의 출발점은 Grootendorst (2022), sentence-bert-embedding 은 Reimers & Gurevych (2019), patent text mining 에서 PatentBERT (Lee & Hsiang 2020), DeepPatent (Li et al. 2018), 그리고 직접 사용한 PatentSBERTa (Bekamiri et al. 2024). 방법론적으로 Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT 자매 작업과 동일 BERTopic 파이프라인을 공유. 황준석 의 4기-5기 (2020-2026 경계) text mining·기술 동향 분석 라인의 작업이며, special section “Sustainable, smart and inclusive growth within entrepreneurial and innovation knowledge-driven ecosystems” (guest editors: Cunningham, Carayannis, Miller, O’Kane, Theodoraki, Ferreira) 의 일부.
See also
- 황준석
- Jihye Lim
- Journal of Knowledge Management
- 지식 경영
- 테크노스트레스
- Sustainability
- collaboration
- BERTopic
- sentence-bert-embedding
- patentsberta-similarity
- 토픽 모델링
- Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT
인접 그래프
- 인물 2
- 방법론 2
- 개념 2
- 수록처 2
- 분류 1
- 논문 2