Measuring ethics level of technological topics using phylogenetic tree
Dawoon Jeong, Chanlim Park, Taewon Kang, Kiyoon Shin, Sungjun Choi, 황준석 (2024) · Technology Analysis & Strategic Management 36(11):3417-3430 · DOI ↗
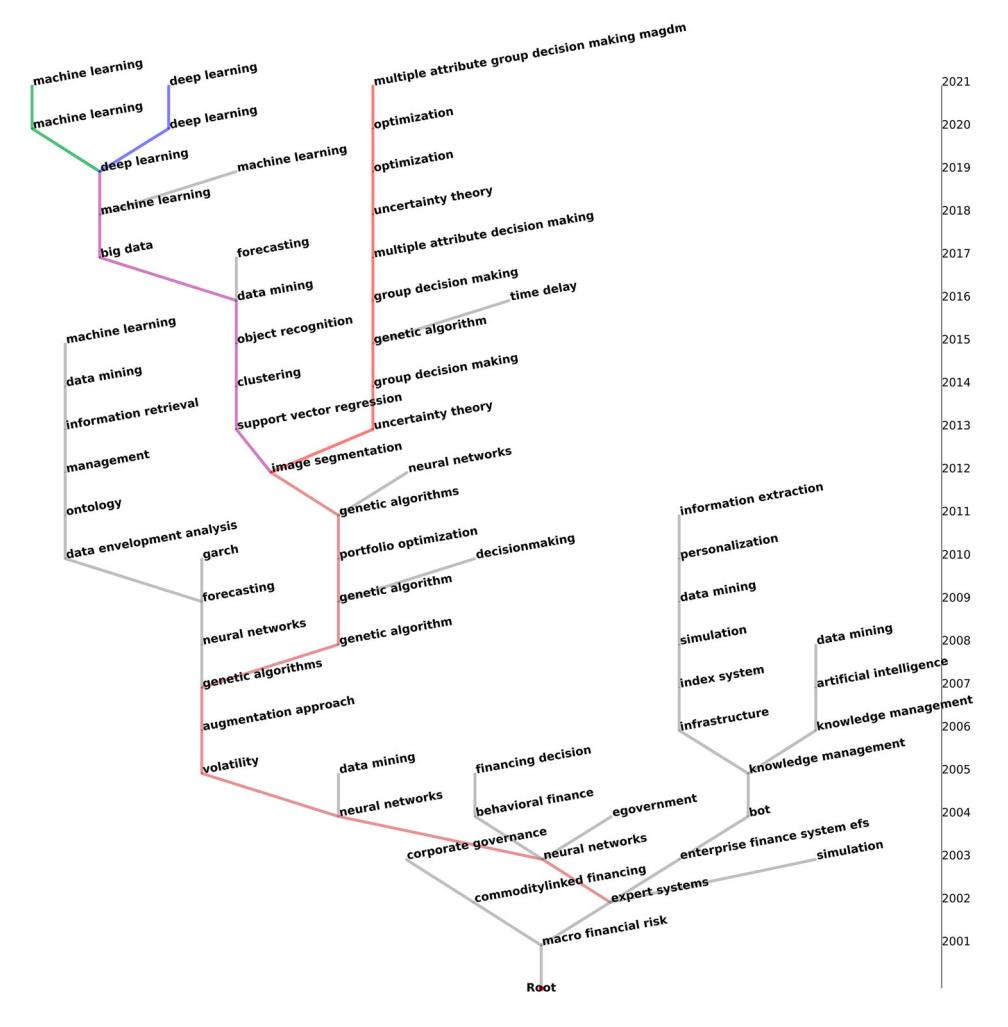
금융 AI 기술의 진화 패턴을 계통수 위에서 가시화하고, 각 토픽이 fairness · 인권 · 투명성 · 프라이버시 · 설명가능성 · 성능보장 6 개 윤리 속성을 어느 강도로 논의하는지 NLP 기반 ethical token 빈도로 정량화. Web of Science 의 finance 검색 + computer science / AI 카테고리 6,755 papers (2001~2021) 를 Doc2Vec 으로 임베딩하고, 연도별 community 를 Girvan-Newman 으로 추출, jensen-shannon-divergence 로 ancestor-descendant 관계를 매칭해 phylogenetic tree 를 구축. 2021 년 finance AI 는 deep learning · machine learning · decision-making 의 세 토픽으로 분기.
- RQ: 기술 토픽의 진화적 구조 위에서 AI ethics 속성 (fairness, explainability 등) 의 강도를 어떻게 정량적으로 측정할 수 있는가, 그리고 토픽별로 어떤 속성이 강조되는가.
- 방법론: 계통수, Doc2Vec, Word2Vec, girvan-newman-community-detection, jensen-shannon-divergence, 토픽 모델링, delphi-method
- 데이터: Web of Science “finance” query × Computer Science AI 카테고리 6,755 paper abstracts (2001-2021). Doc2Vec 100D 벡터 (window=3, min_count=1), cosine similarity threshold 0.3 으로 연간 paper network 구축, ≥ 10 paper 인 community 만 topic 으로 정의.
- 주요 발견: (i) 2021 년 finance AI 는 3 개 토픽으로 수렴 — deep learning (418 papers), machine learning (302), decision-making (116). (ii) topic 별 윤리 강조점 상이 — deep learning 은 explainability + performance, machine learning 은 privacy + security, decision-making 은 human rights + normality. (iii) 세 토픽 모두 fairness 논의가 가장 낮음 — finance AI 전반의 공통 사각지대.
- 시사점: 데이터 기반 ethical level 측정으로 정책·연구 우선순위 설정의 정량 evidence 제공. fairness 가 가장 시급한 논의 영역.
요약
황준석 의 AI 정책·기술 평가 라인 (5기 AI 와 국가 경쟁력) 과 이정동 의 계통수 방법론 라인 (Mapping the Evolutionary Pattern of Mobile Products: A Phylogenetic Approach) 이 교차하는 작업. 기존 AI 윤리 연구는 (i) Jobin et al. 류의 가이드라인 meta-analysis, (ii) Delphi 같은 전문가 합의 위주로 정성적인 한계가 있었다. 본 paper 는 “연구 paper text 자체에서 윤리 논의 강도를 측정” 하는 quantitative pipeline 을 제안해 이 공백을 메운다.
방법론은 4 단계. (i) Doc2Vec 으로 abstract 를 100D 벡터화 (Word2Vec 의 paragraph 확장). (ii) 연도별 cosine similarity ≥ 0.3 network 에서 Girvan-Newman algorithm 으로 modularity 최적 community 추출, ≥ 10 paper 인 것을 topic 으로 정의. (iii) 인접 시점 topic 간 jensen-shannon-divergence 최소화로 ancestor 식별 — argmin 으로 ancestor-descendant edge 형성. (iv) 한국 TTA (Telecommunications Technology Association) 의 AI 윤리 가이드라인 6 속성별로 4 개 representative token (예: fairness → “fair, discrimin, imparti, inclin”) 을 Delphi 로 선정, Word2Vec 으로 유사 token 확장한 token set 의 abstract 출현 빈도 합으로 EL (Ethics Level) 계산. radar chart 로 6 속성을 표준화 (max = 1) 비교.
결과의 함의는 셋. 첫째, finance AI 는 2010 년 최다 토픽 분기 (speciation 시기) 를 거쳐 2021 년 3 개로 안정화 — decision-making 은 2012 년 이후 단일 lineage 로 stable niche 형성, deep/machine learning 은 여전히 분화 중. 둘째, 토픽별 윤리 강조점 차이는 기술의 응용 맥락 (resource optimization, decision support, performance) 과 일치한다 — privacy 가 machine learning 에서 중요한 이유는 portfolio optimization, genetic algorithm 같은 keyword 가 자원배분 보안 이슈와 연결되기 때문. 셋째, fairness 가 모든 토픽에서 최하 — finance AI 의 사회적 영향 (예: 2021 한국 챗봇 ‘이루다’ 사례) 을 고려할 때 정책·연구 보완 시급. 한계는 ethical token set 이 expert Delphi 기반이라 token selection 의 qualitative 의존성이 남는다는 점.
핵심 결과
2021 년 finance AI 의 3 개 토픽별 ethical level (radar chart 의 상대값, max = 1):
| Topic | Papers | 최강 속성 | 2위 | 최약 속성 |
|---|---|---|---|---|
| Deep Learning (blue) | 418 | explainability + performance guarantees (동률) | privacy/security | fairness |
| Machine Learning (green) | 302 | privacy + security | performance | fairness |
| Decision-Making (red) | 116 | human rights + normality | transparency | fairness |
- 공통 사각지대: 세 토픽 모두 fairness 가 최하. finance AI 전체 영역에서 공정성 논의 보완 필요.
- 토픽별 응용 맥락 일치: machine learning 의 portfolio optimization 키워드 → privacy/security 강조, deep learning 의 neural network 복잡성 → explainability 강조.
- 진화 안정성: decision-making 은 2012 년 이후 단일 lineage (점진적 개선 전략 적합), deep/machine learning 은 active speciation (도전적 전략 적합).
방법론 노트
계통수 는 생물 진화에서 horizontal gene transfer, hybrid, gene loss 를 관찰하는 도구로 출발했으며, Chavalarias & Cointet (2013) 이후 phylomemetic tree 형태로 과학·기술 진화 분석에 차용되어 왔다. 본 paper 의 차별점은 keyword 가 아니라 paper 자체를 단위로 한 community 기반 토픽 정의 — 기존 keyword 단위 분석의 “기술적 의미가 약한 일반 단어가 토픽 키워드로 잡히는” 문제를 회피.
핵심 식 1 — 연간 paper network 구축:
여기서 (적정 community 수 산출 threshold), 는 시점 paper 의 Doc2Vec 100D 임베딩.
핵심 식 2 — ancestor 식별 (JSD 최소화):
여기서 는 시점 의 topic (paper 집합), 는 그 토픽의 cleaned token 분포. JSD 는 KLD 의 비대칭성을 보완한 distance.
핵심 식 3 — Ethics Level (EL):
는 6 윤리 속성 중 하나, 는 그 속성을 표현하는 token set (Delphi + Word2Vec 유사 확장), 는 토픽 내 paper. 즉 토픽 내 모든 paper abstract 에서 윤리 token 출현 총합. 토픽별로 max EL = 1 로 표준화해 radar chart 로 비교.
연구 계보
Dawoon Jeong 의 product/technology phylogeny 라인 — Where and how does a product evolve? Product innovation pattern in product lineage 와 Mapping the Evolutionary Pattern of Mobile Products: A Phylogenetic Approach 가 모바일 제품 진화를 phylogenetic 으로 분석한 직계 ancestor. 본 paper 는 그 방법론을 (i) 분석 단위를 product 에서 research topic 으로, (ii) 출력을 lineage map 에서 ethical attribute overlay 로 확장한다. AI 윤리 측면에서는 Jobin, Ienca & Vayena (2019, Nature Machine Intelligence) 의 글로벌 가이드라인 meta-analysis 와 Hagendorff (2020) 의 22 개 가이드라인 비교가 핵심 reference. Zhang et al. (2021, Knowledge-Based Systems) 의 AI ethics bibliometric 분석은 직접 비교 대상 (keyword 단위 vs. token 단위). 한국 TTA AI 윤리 가이드라인 (Delphi 기반) 이 6 속성 분류의 source. Doc2Vec (Le & Mikolov 2014), Girvan-Newman (Newman & Girvan 2004) 은 방법론 building block. 황준석 라인 (5기 AI 와 국가 경쟁력 — AI technology specialization and national competitiveness, Dynamic patterns of AI technology diffusion: focusing on time series clustering and patent analysis) 의 AI 정량 분석 흐름과 자매.
See also
- 황준석
- Dawoon Jeong
- Taewon Kang
- Kiyoon Shin
- 계통수
- 토픽 모델링
- AI 윤리
- Doc2Vec
- Technology Analysis & Strategic Management
- Mapping the Evolutionary Pattern of Mobile Products: A Phylogenetic Approach
- Where and how does a product evolve? Product innovation pattern in product lineage
인접 그래프
- 인물 7
- 방법론 3
- 개념 1
- 주제 1
- 수록처 1
- 분류 2
- 논문 6