Exploring trends and topics in hybrid intelligence using keyword co-occurrence networks and topic modelling
Jihye Lim, 황준석 (2025) · Futures 167:103550 · DOI ↗
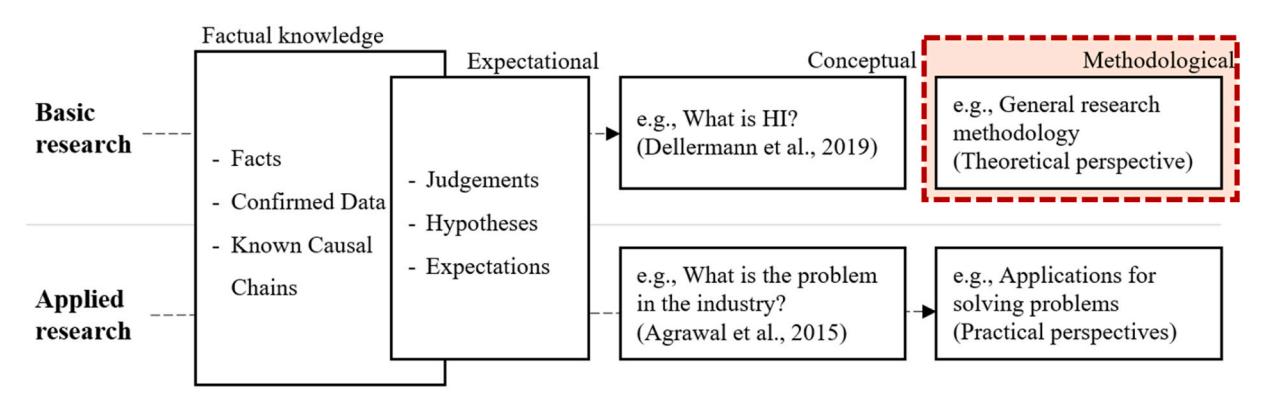
인간-AI 협력 패러다임으로서 hybrid intelligence (HI) 분야 20 년 (2003-2022) 의 연구 동향을 Keyword Co Occurrence Network (KCN) + Latent Dirichlet Allocation (LDA) 으로 매핑. PRISMA 가이드라인을 따라 Scopus 의 두 search string (“hybrid intelligence” + ChatGPT 가 제안한 299 synonyms) 으로 369 paper 수집 후 manual 검증으로 170 paper 확정. 4 trending topic (decision making · medical science · social factors · automation) 과 3 emerging topic (crowdsourcing · data science · teamwork) 식별. Wiig (1993) 의 4 knowledge type (factual / conceptual / expectational / methodological) 분류로 basic-methodological (research methodology 로서의 HI) 가 3% 에 불과한 사각지대 지적.
- RQ1: HI 분야의 leading research area 와 trending topic 은 무엇인가. RQ2: HI 의 emerging / promising topic 은 무엇인가.
- 방법론: Keyword Co Occurrence Network (Barrat et al. 2004 weighted network), Latent Dirichlet Allocation (Blei et al. 2003, coherence score 기반 k=7), PRISMA 체계적 문헌 리뷰, NLTK lemmatization, ChatGPT 기반 synonym 확장.
- 데이터: Scopus 2003-2022, 4 time window (2003-08, 2008-12, 2013-17, 2018-22). PRISMA 후 170 paper 확정 (article + conference paper). subject area 는 Scopus 분류 기준 (computer science 21.76% top, engineering, mathematics 등).
- 주요 발견: (i) 2017 (Transformer 등장) + 2018 이후 HI 연구 폭증, computer science / engineering / mathematics 가 main field. (ii) 4 trending topic: decision making, medical science, social factors, automation. (iii) 3 emerging topic: crowdsourcing, data science, teamwork. (iv) knowledge type 사각지대: basic-methodological knowledge (HI 를 연구 방법론으로 활용) 가 170 paper 중 5 편 (3%) 에 불과 — 가장 큰 미개척 영역.
- 시사점: HI 를 연구 방법론으로 활용하는 새 분야 개척 필요. AI 중심 funding 정책을 HI (human 통합) 로 확장 권고. policymaker 에게 미래 고용·부 분배 전망의 evidence 제공.
요약
황준석 의 5기 (AI 와 국가 경쟁력) 라인의 systematic literature review 분기. Jihye Lim 의 SNU TEMEP 박사 라인 + Smart City Innovative Talent Education Program 펀딩으로 산출. 자매 Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT (스마트시티 협력자 관심 토픽) 와 동일 author 의 method 라인 — LDA + KCN 을 다른 domain (스마트시티 → HI) 에 응용. 기존 systematic review 들 (Dellermann et al. 2021, Hemmer et al. 2021, Wiethof & Bittner 2021, Correia et al. 2023) 이 design / collaboration / learning pattern 등 부분 영역만 다룬 것에 비해, 본 paper 는 (i) 20 년 long-window, (ii) KCN + LDA 결합, (iii) knowledge type 분류까지 통합한 first comprehensive map.
방법론은 4 step. (i) data collection: PRISMA 가이드라인으로 Scopus 에서 두 search string — string 1 (“hybrid intelligence” AND “human”/“man”) 으로 pure AI 의 “hybrid” 와 구분, string 2 (synonyms — ChatGPT 가 10 회 반복으로 299 단어 제안, 중복 제거 + 관련도 필터 후 사용) 로 광범위 capture. 369 → 170 paper (manual relevance 검증). (ii) preprocessing: acronym 통일, 유사어 그룹화 (e.g., deep/machine learning), lemmatization (NLTK), 비정보 단어 제거. (iii) KCN: weighted network 에서 node degree , average link weight , node strength 의 3 measure (Barrat et al. 2004) 로 quantitative + visual 분석, 4 time window 로 진화 추적. (iv) LDA: title + abstract 로 unsupervised topic extraction, coherence score (UMass) 로 optimal k=7 결정.
핵심 발견은 셋. 첫째, 출판 trend 는 2017 (Vaswani et al. Transformer) → 2018 이후 exponential. 둘째, trending vs emerging 의 구분: trending (decision making, medical science, social factors, automation) 은 LDA + KCN 양쪽에서 일관 식별, emerging (crowdsourcing, data science, teamwork) 은 Window 4 (2018-22) 의 keyword strength 에서 새로 등장. 셋째, knowledge type 비대칭 — Wiig (1993) 의 4 type 분류로 170 paper 를 매핑하면 applied-methodological 87 (51%), applied-conceptual 41 (24%), basic-conceptual 37 (22%), basic-methodological 5 (3%). 즉 HI 를 “연구 방법론 그 자체” 로 활용한 연구는 거의 없다. 저자는 이를 가장 promising future direction 으로 제시. 한계: search term 의 field-specific 누락 가능성, Scopus 한정, title/abstract 만 (full text 미포함), manual selection 의 evaluator bias.
핵심 결과
| Rank | Top 7 LDA topics | Top 7 KCN keywords | Final trending topics |
|---|---|---|---|
| 1 | Interaction design | Decision making | Decision making |
| 2 | Social knowledge | Medical science | Medical science |
| 3 | Decision making & business | Knowledge management | Social factors |
| 4 | Automation | Crowdsourcing | Automation |
| 5 | Social cognition | Social | |
| 6 | Medical science | Human factor | |
| 7 | Organization design | Automation |
- Trending topic: Decision making, Medical science, Social factors, Automation.
- Emerging topic (Window 4 신규): Crowdsourcing, Data science, Teamwork.
- Knowledge classification (Wiig 1993): basic-conceptual 37 / basic-methodological 5 (3%) / applied-conceptual 41 / applied-methodological 87. → “HI 를 research methodology 로” 가 가장 큰 미개척.
- Window 4 (2018-22) top-strength keyword: AI 258, decision making 71, medical science 39, crowdsourcing 39, data science 35, knowledge management 35.
- Window 1 (2003-07) vs Window 4 strength gap: 2배 → 9.5배 (toptier 토픽 집중도 증가 + 새 토픽 출현).
방법론 노트
Keyword Co Occurrence Network (KCN) 의 weighted network 분석 (Barrat et al. 2004). adjacency matrix 에서:
Node degree (단순 link 수):
여기서 if link exists, otherwise.
Average link weight (degree 결합):
Node strength (link 의 weight 까지 반영, weighted network 의 적절한 importance):
Latent Dirichlet Allocation (LDA, Blei et al. 2003) 은 unsupervised topic model 로 토픽 분포와 단어 분포를 동시 추정. optimal (topic 수) 는 coherence score (UMass) 로 결정:
는 단어 의 paper 빈도, 는 두 단어가 동시 등장한 paper 수. 본 paper 는 coherence score + manual review 로 채택. perplexity 는 Hasan et al. (2021) 의 비판에 따라 부수적.
KCN 과 LDA 는 상호 보완 — KCN 은 author keyword 만, LDA 는 abstract + title 의 hidden topic 까지 capture. 두 결과의 교집합으로 trending topic 의 신뢰도 확보.
연구 계보
황준석 의 5기 (AI 와 국가 경쟁력 · 토픽 모델링 방법론) 라인. 같은 author / 같은 method 라인의 직계 ancestor 는 Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT (스마트시티 협력자 토픽, Heliyon 2024) — 본 paper 는 그 method 를 스마트시티에서 HI 로 확장. 자매 paper 로는 Dynamic patterns of AI technology diffusion: focusing on time series clustering and patent analysis (시계열 클러스터링 + AI 특허 분석, Scientometrics) 과 Measuring ethics level of technological topics using phylogenetic tree (phylogenetic + LDA, finance AI ethics) 가 황준석 author page anchor 의 “AI 와 국가 경쟁력 / 토픽 모델링 / 계량 분석” 라인의 동족. AI technology specialization and national competitiveness (국가별 AI 특화) 와 함께 5기 AI 분기를 구성. 기술적 reference 는 (i) HI 정의: Lomov & Venda (1977) 의 원조, Dellermann et al. (2019, BISE) 의 표준 정의 (collective + superior + continuous learning), van der Aalst (2021) 의 human vs AI strength 대비. (ii) KCN: Barrat et al. (2004, PNAS) 의 weighted network architecture, Radhakrishnan et al. (2017). (iii) LDA: Blei, Ng & Jordan (2003, JMLR) 의 원조, Yu & Xiang (2023) 의 AI 토픽 모델링. (iv) Knowledge classification: Wiig (1993) 의 KM 4 type model. (v) PRISMA: Page et al. (2021). 이정동 author page anchor 의 토픽 모델링 도구 라인과도 방법론 연결.
See also
- 황준석
- Jihye Lim
- Futures
- Hybrid Intelligence
- Keyword Co Occurrence Network
- Latent Dirichlet Allocation
- 토픽 모델링
- Human Ai Collaboration
- Exploring diverse interests of collaborators in smart cities: A topic analysis using LDA and BERT
- Dynamic patterns of AI technology diffusion: focusing on time series clustering and patent analysis
- Measuring ethics level of technological topics using phylogenetic tree
- AI technology specialization and national competitiveness
인접 그래프
- 인물 3
- 방법론 4
- 주제 2
- 수록처 1
- 분류 2
- 논문 5