Measuring consumption efficiency with utility theory and stochastic frontier analysis
이정동, Chansoo Park, Dong-Hyun Oh, Tai-Yoo Kim (2008) · Applied Economics 40(22):2961–2968 · DOI ↗
생산 efficiency 의 frontier 개념을 소비 영역으로 확장한 두 번째 라운드. Estimating consumers' willingness to pay for individual quality attributes with DEA 가 DEA 의 deterministic frontier 로 풀었던 같은 문제를 — 다속성 차별재 시장에서의 consumption inefficiency — 이번엔 SFA (확률적 프론티어 분석) 의 확률적 frontier 로 다시 푼다. 이론적 핵심은 Diewert (2001) 의 utility-theoretic hedonic regression 에 one-sided inefficiency term 와 two-sided noise term 를 결합한 hedonic stochastic frontier equation 도출. 2002 Q1 한국 PC 시장 572 모델에 적용해 평균 consumption efficiency ≈ 86.6%, 대기업 (diversified chaebol) 의 가격은 같은 품질에서 더 비싸 (낮은 효율), PC 전문 중견사는 더 효율적이라는 brand effect 확인. high-end 제품일수록 efficiency 가 낮다 — early adopter premium 의 정량 증거.
- RQ: 다속성 소비재의 consumption inefficiency 를 utility maximization framework 에서 어떻게 정의·도출하고, SFA (확률적 프론티어 분석) 의 확률적 frontier 로 어떻게 추정하는가? 한국 PC 시장에서 brand·high-end 가 efficiency 에 어떤 영향을 미치는가?
- 방법론: SFA (확률적 프론티어 분석) (battese-coelli-1995-model 의 inefficiency-effects 모델, half-normal truncated), hedonic-price-function (Rosen 1974 + Diewert 2001 utility-theoretic foundation), utility-theory (expenditure-minimization 도출), composite-quality index
- 데이터: 한국 PC 시장 2002 Q1, 572 모델. quality 변수: CPU speed (MHz), RAM (MB), HDD (GB), CPU type dummies (PIII/PIV), CD-RW · DVD-ROM · 무선 LAN dummies. firm dummies (S, U, H, Y, L, T — 대기업 vs PC 전문사 구분) 는 inefficiency 함수로 분리
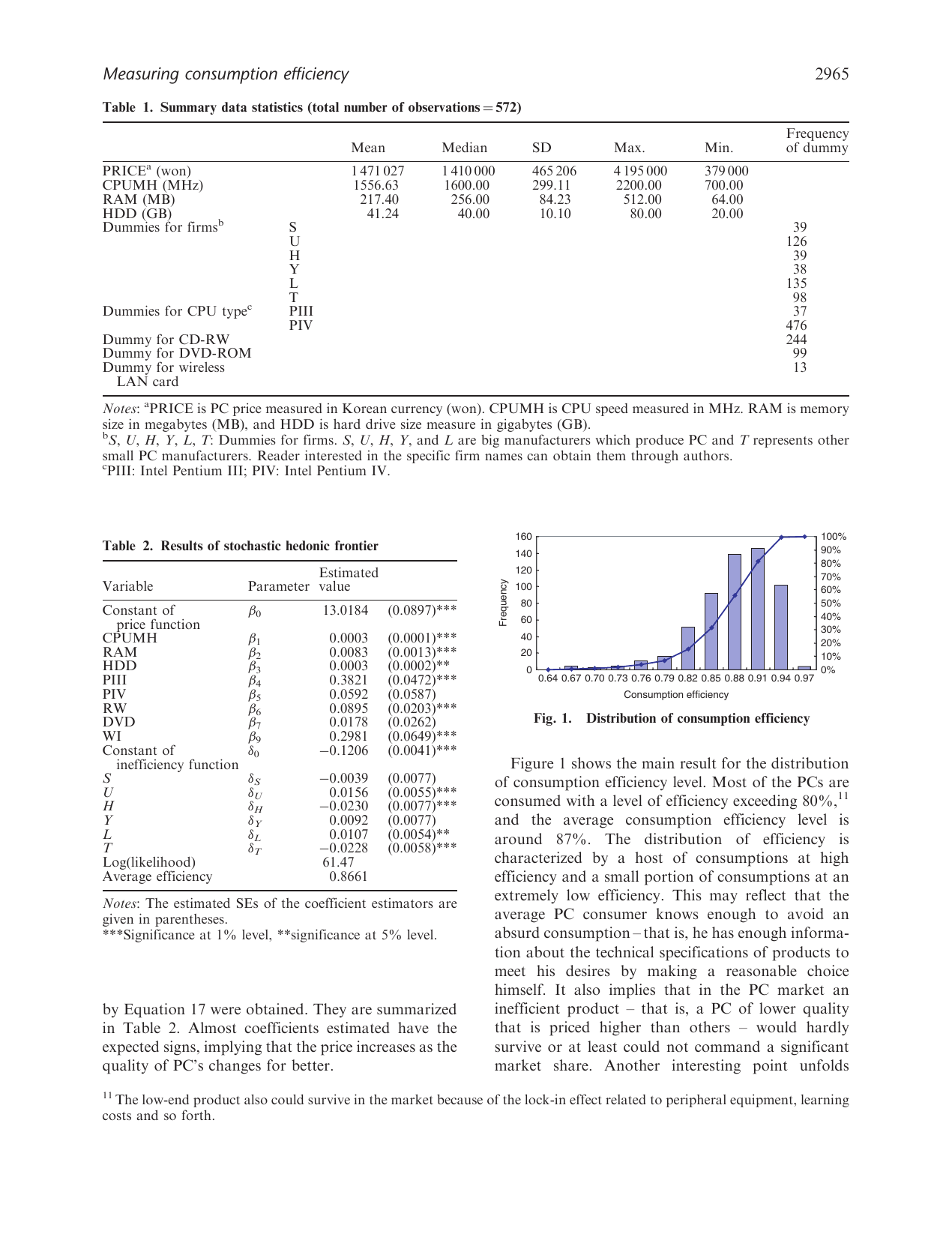
- 주요 발견: (i) 평균 consumption efficiency ≈ 0.866 (대부분 PC 가 80% 이상 efficiency), (ii) 다각화 대기업 (chaebol) U·Y·L 의 양(+) — 같은 품질에 더 비싼 가격 → 낮은 efficiency. PC 전문 H·T 의 음(−) — 더 효율적, (iii) high-end 제품의 efficiency 가 체계적으로 낮음. 특히 CPU MHz 가 높을수록 inefficiency 증가 (early adopter premium + monopolistic CPU 시장)
- 시사점: hedonic frontier 라는 새 개념이 가격-품질 산점도의 하한 을 정의 — traditional 평균 hedonic regression 은 산점도 중앙 line. brand value · 신제품 premium 등 비관측 품질 의 효과를 efficiency gap 으로 측정 가능. 제조사의 가격책정, marketing 의 segmentation 분석에 직접 활용
요약
생산 efficiency 가 1960 년대부터 measurable 한 frontier 개념으로 발달했지만 소비 가 inefficient 일 수 있다는 질문은 상대적으로 미답이었다. Lancaster (1966), Hjorth-Andersen (1984), Kamakura-Ratchford-Agrawal (1988), Varian (1990), Ley-Steel (1996) 의 산발적 연구가 이 공간을 열었고, 이정동 그룹은 두 번에 걸쳐 이 문제를 풀었다 — Estimating consumers' willingness to pay for individual quality attributes with DEA (DEA · range-adjusted-model) 와 The Measurement of Consumption Efficiency Considering the Discrete Choice of Consumers (discrete choice + RA-FDH). 본 paper 는 그 시리즈의 세 번째 도구 — SFA (확률적 프론티어 분석) 로 확률적 frontier 를 그려 random noise 와 systematic inefficiency 를 분리하는 econometric 접근이다.
이론적 contribution 은 Diewert (2001) 의 utility-theoretic hedonic regression framework 에 consumption inefficiency term 을 명시적으로 끼워넣은 도출 과정이다. 대표 소비자가 hedonic good + numeraire 를 소비할 때 inefficient 한 선택이면 같은 utility 에 도달하기 위해 만큼만 잔여 numeraire 가 남는다 — 가 inefficiency 도. 이를 expenditure-minimization 의 1차 조건과 Euler 정리 (homogeneous degree 1) 로 정리하면 의 hedonic frontier 가 도출되고, 여기에 random error 를 더해 의 SFA (확률적 프론티어 분석) 모델이 된다. 는 truncated normal, 는 — battese-coelli-1995-model 표준 specification. 추가로 firm dummies 를 inefficiency 함수의 covariate () 로 분리, 가격 함수와 inefficiency 함수를 한 번에 추정.
실증은 2002 Q1 한국 PC 시장 572 모델. 평균 efficiency = 0.866 (Fig. 1 의 분포), 가격 회귀 계수는 모두 예상 부호 (CPU·RAM·HDD·dummies). 핵심 발견은 firm dummies 의 부호 비대칭 — diversified chaebol (U·Y·L) 은 (같은 품질에 더 비싼 가격 → 낮은 efficiency), PC 전문 중견사 (H·T) 는 (더 효율적). brand value 가 price premium 으로 표출되는 efficiency 측정의 직접 증거. 또한 composite-quality 와 efficiency 의 산점도 (Fig. 2-4) 가 high-end 제품일수록 inefficient 라는 패턴을 일관되게 보여준다 — early adopter 의 newness premium, 그리고 CPU 시장의 monopolistic 가격책정 (Intel 의 신세대 CPU 가격 over-pricing) 이 그 원인.
세 한계가 명시적이다. 첫째, sample 이 PC 시장 한 시점 cross-section 이라 demand-side vs supply-side inefficiency 분리가 불가능 — paper 도 conclusion 에서 individual market share data 가 있으면 분리 가능하다고 시사. 둘째, brand value 같은 비관측 quality 가 inefficiency term 으로 흡수되므로 진짜 “비효율” 인지 “측정 안 된 품질” 인지 구별 불가 — paper 본문 (Footnote 2) 에서 인정. 셋째, hedonic frontier 의 functional form (log-linear) 이 가정에 강하게 의존 — translog 등 flexible form 으로의 robustness check 부재. 그럼에도 본 paper 의 contribution 은 consumption inefficiency 라는 개념을 utility theory 의 1차 조건에서 formal 하게 도출한 것 — Kamakura et al. (1988) 의 DEA 직접 적용이나 Lee et al. (2005) 의 RA-FDH 와 달리 utility-theoretic foundation 을 명시적으로 노출한 셈.
핵심 결과
Stochastic hedonic frontier 추정 (Table 2, 회귀, N=572)
| Variable | Parameter | Estimate (SE) | Sig |
|---|---|---|---|
| Constant | 13.0184 (0.0897) | *** | |
| CPU speed (MHz) | 0.0003 (0.0001) | *** | |
| RAM (MB) | 0.0083 (0.0013) | *** | |
| HDD (GB) | 0.0003 (0.0002) | ** | |
| Pentium III dummy | 0.3821 (0.0472) | *** | |
| Pentium IV dummy | 0.0592 (0.0587) | n.s. | |
| CD-RW dummy | 0.0895 (0.0203) | *** | |
| DVD-ROM dummy | 0.0178 (0.0262) | n.s. | |
| Wireless LAN dummy | 0.2981 (0.0649) | *** |
Inefficiency 함수 firm 계수 ()
| Firm group | Type | 해석 | |
|---|---|---|---|
| 상수 | — | −0.1206*** | baseline inefficiency |
| S | 중견 PC | −0.0039 (n.s.) | neutral |
| U | 다각화 대기업 | +0.0156*** | low efficiency (brand premium) |
| H | 중견 PC | −0.0230*** | high efficiency |
| Y | 다각화 대기업 | +0.0092 (n.s.) | low-eff tendency |
| L | 다각화 대기업 | +0.0107** | low efficiency (brand premium) |
| T | 중견 PC | −0.0228*** | high efficiency |
| 평균 efficiency | — | 0.8661 | log L = 61.47 |
*** p<0.01, ** p<0.05. diversified vs specialized firm 의 부호 비대칭이 본 paper 의 핵심 정량 발견.
방법론 노트
utility-theory 의 expenditure-minimization 으로부터 hedonic frontier 를 도출하고, 거기에 random noise 를 더해 SFA (확률적 프론티어 분석) 모델로 만든다. Inefficiency term 이 one-sided (price 가 frontier 위 쪽 으로만 벗어남) 인 것이 핵심 — frontier 가 가격-품질 공간의 하한 (가장 효율적인 소비) 이기 때문.
핵심 식. utility 의 expenditure-minimization → Euler 정리 (homogeneous degree 1) + linear log-hedonic 가정 → random error 추가:
여기서 는 hedonic good 의 가격, 는 의 번째 품질 attribute, 는 attribute 의 implicit price, 은 consumption inefficiency (one-sided, truncated normal), 은 random noise (two-sided).
battese-coelli-1995-model 처럼 inefficiency 가 covariate 에 의존:
개별 obs 의 efficiency 는 Jondrow-Lovell-Materov-Schmidt 공식:
with , . ML 로 가격 함수와 inefficiency 함수를 동시 추정. 식별은 (i) 가격 함수의 frontier 가 upper envelope 이라는 one-sided 가정, (ii) inefficiency 함수의 covariate (firm dummies) 가 frontier 함수의 quality variables 와 non-collinear 라는 dual specification 에서 온다.
composite-quality 는 — discrete choice theory 의 “deterministic utility” (Anderson-Palma-Thisse 1992) 와 동일 — 다속성 quality 를 1 차원 scalar 로 압축해 efficiency-quality 관계를 산점도화 가능하게 만든다.
연구 계보
본 paper 는 Lancaster (1966 JPE) 의 product characteristics theory, Rosen (1974 JPE) 의 hedonic price function, Diewert (2001) 의 utility-theoretic hedonic foundation, Battese-Coelli (1995 Empirical Economics) 의 inefficiency-effects SFA model, 그리고 Kumbhakar-Lovell (2000) 의 SFA 표준 textbook 을 결합한 cross-domain 융합. consumption efficiency 의 사상적 lineage 는 Lancaster → Hjorth-Andersen (1984) → Kamakura-Ratchford-Agrawal (1988, DEA 첫 적용) → Varian (1990, money-metric utility) → Ley-Steel (1996, Bayesian) 으로 이어지고, 본 paper 는 그 series 의 SFA 버전.
이정동 의 consumption efficiency 라인 내부에서 본 paper 의 위치는 명확하다 — 직전 작업 Estimating consumers' willingness to pay for individual quality attributes with DEA 는 DEA 의 deterministic frontier 로 같은 문제를 풀었고, 같은 그룹의 The Measurement of Consumption Efficiency Considering the Discrete Choice of Consumers (Lee-Hwang-Kim 2005 Journal of Productivity Analysis) 는 discrete choice 의 discreteness 를 강조한 RA-FDH 변형. 본 2008 paper 는 SFA 도구로 random noise 와 inefficiency 를 통계적으로 분리한 세 번째 라운드 — DEA 의 deterministic 한계 (모든 deviation 을 inefficiency 로 간주) 를 극복한다. author page 분류상 1990 년대 후반 DEA 기반 productivity 시리즈 (Technological Progress versus Efficiency Gain in Manufacturing Sectors, Productivity growth, capacity utilization, and technological progress in the natural gas industry) 다음의 SFA 확장기에 해당한다.
See also
- SFA (확률적 프론티어 분석)
- hedonic-price-function
- utility-theory
- battese-coelli-1995-model
- consumption-inefficiency
- composite-quality
- Estimating consumers' willingness to pay for individual quality attributes with DEA
- The Measurement of Consumption Efficiency Considering the Discrete Choice of Consumers
- 이정동
- Tai-Yoo Kim
인접 그래프
- 인물 4
- 방법론 2
- 수록처 1
- 분류 2
- 논문 4